每日文章收集-20230707
【今日关注】
node-crawler:NodeJS端的网络爬虫框架
NodeJS端最强大,最受欢迎的爬虫包。主要Feature:
- 服务器端DOM和自动插入jQuery使用Cheerio(默认)或JSDOM,
- 可配置的连接池大小和重试次数,
- 控制请求速率限制,
- 请求的优先级队列,
- forceUTF8模式可让网络爬虫处理字符集的检测和转换,
- 与4.x或更新版本兼容。
安装
1 | $ npm install crawler |
基本用法
1 | const Crawler = require('crawler'); |
限速
使用rateLimit限制爬取速度。
1 | const Crawler = require('crawler'); |
自定义参数
当需要从前一个请求或响应中获取参数时,可以通过options来传递。
1 | c.queue({ |
随后在回调函数中通过res.options来获取该参数。
1 | console.log(res.options.parameter1); |
crawler只会将必要的参数通过options传递,所以不用担心冗余。
响应数据
如果是下载文件的请求,比如图片,文档,pdf等,你需要让crawler不要将响应数据转换为string类型,这时将encoding参数设置为null。
1 | const Crawler = require('crawler'); |
预请求(preRequest)
如果您希望在每个请求之前以同步或异步方式执行某些操作,可以尝试下面的代码。请注意,直接的请求不会触发 preRequest。
1 | const c = new Crawler({ |
【博文一览】
InternLM:70亿参数的新开源大语言模型
这是一个国产的大语言模型,中文名叫书生·浦语。以下均来自github的介绍。
InternLM ,即书生·浦语大模型,包含面向实用场景的70亿参数基础模型与对话模型 (InternLM-7B)。模型具有以下特点:
- 使用上万亿高质量预料,建立模型超强知识体系;
- 支持8k语境窗口长度,实现更长输入与更强推理体验;
- 通用工具调用能力,支持用户灵活自助搭建流程;
提供了支持模型预训练的轻量级训练框架,无需安装大量依赖包,一套代码支持千卡预训练和单卡人类偏好对齐训练,同时实现了极致的性能优化,实现千卡训练下近90%加速效率。
开源评测工具 OpenCompass 从学科综合能力、语言能力、知识能力、推理能力、理解能力五大能力维度对InternLM开展全面评测,部分评测结果如下表所示。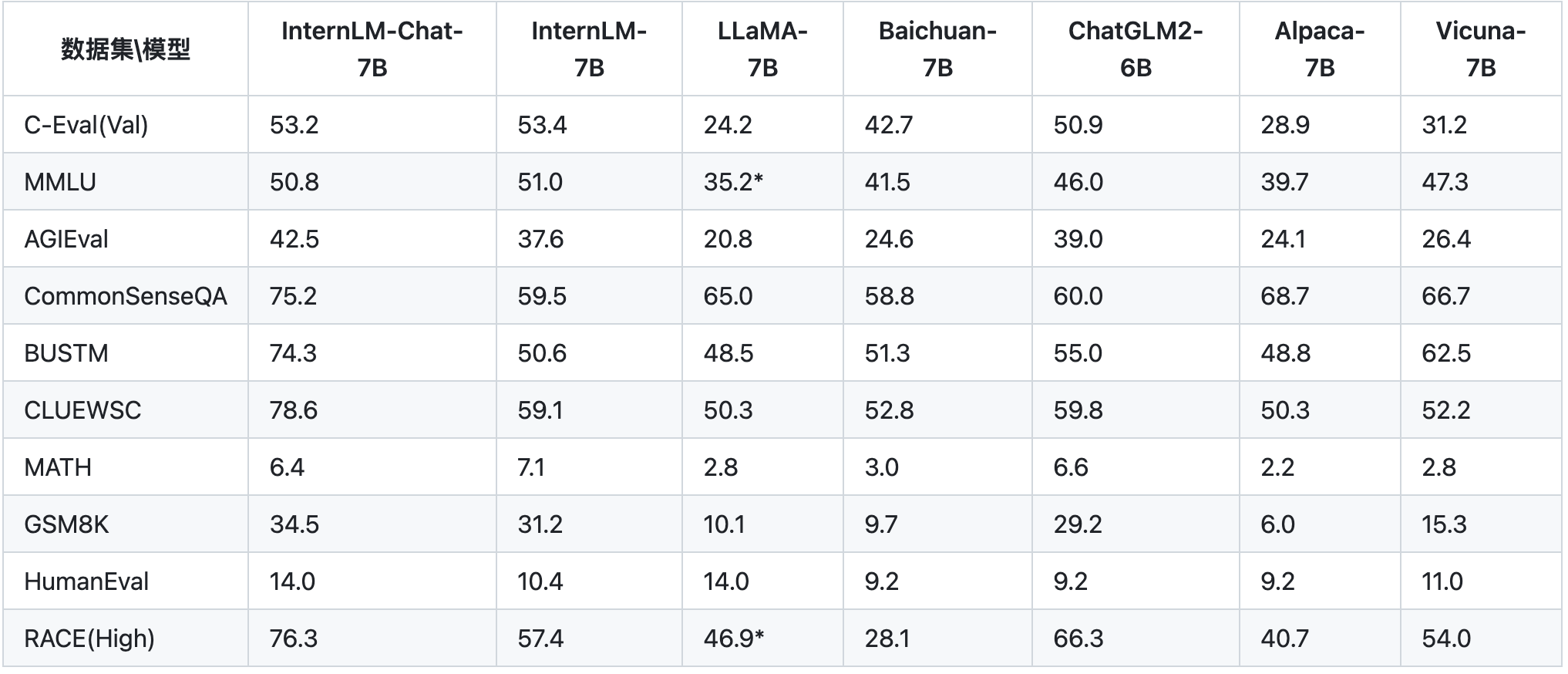
Evernote已经几乎解雇了所有的员工
Evernote在中国的名字是大名鼎鼎的“印象笔记”,大部分人可能都用过,太久没打开过印象笔记,我都快忘了这个软件,如今却听到了它的这么一个不好的消息。
如今其收购者(Bending Spoons)已接管了运营。他们还提高了订阅价格,并告知客户他们打算利用新的收入来支付新功能。
在Hacker News上许多人对这条新闻发出感慨,摘录一些。
我觉得Evernote是试图将免费用户转变为付费用户,但却面临了痛苦的典型例子,这是我们在许多风险投资支持的软件中看到的情况。一旦你免费提供了某项服务,即使你像Evernote那样诚实地解释情况,也几乎不可能收回它。
Evernote曾经很棒。说实话,它是值得付费的。但他们过早地放弃了一切,导致用户感觉他们所拥有的东西被夺走,从而破坏了信任。Obsidian采取了最明智的策略,提供了编辑器,将文件保存在数据库之外,使其具有可移植性(这样,如果需要转移到其他平台,用户会感到安全),并告诉用户,如果他们想拥有同步功能,可以选择付费,在每个设备上获得一致的体验。 ———— belthesar
我认为这是一个尝试对低价值和低成本的东西收费的例子。
在云端存储文本文件非常便宜。而且拥有一个方便编辑这些文件的应用程序也非常便宜。一开始它是免费的,因为这是一个“经典”的软件问题,开发成本低,并且对用户来说成本接近于零。
当Evernote开始为无用的功能收费并锁定我的笔记时,我转而使用了众多免费、开源或非常便宜的替代品之一。
我认为Evernote的问题在于它应该只是一家由1-2人组成的公司。他们增加了成本,然后提高了价格,而顾客们对此并不满意。
这里的教训是要么做有价值的事情,要么做便宜的事情。但不要做没有价值但昂贵的事情。
同步是好的,但可以通过在Dropbox、iCloud或其他平台之上进行层叠来轻松实现笔记的同步。我不想要定制的Evernote同步功能,特别是不愿意为此付与Dropbox一样多的费用。我宁愿只付费使用Dropbox,然后将一堆文件放在其中。 ———— prepend
这就是大多数风险投资支持的创业公司的问题。你投入数百万美元用于一个实际上只是一个经过美化的CRUD服务的应用程序,却最终需要一个由500名工程师和另外3000名员工组成的团队。当真正需要盈利时,这些公司很难做到,因为他们所提供的价值主张实际上并不足够吸引人。
以GrubHub和DoorDash为例。一个基本的订餐系统经过美化之后,是否真的值得支付交易金额的30%作为送餐费?不值得。但必须有人来偿还数十亿美元的无用企业臃肿和数千名员工的开支。 ———— TheKarateKid
Godot:免费的跨平台游戏开发引擎
Godot引擎是一个免费的、全能的跨平台游戏引擎,它使你轻松创建2D和3D游戏变得简单。
主要的feature如下:
- Godot的节点和场景系统为您提供了强大和灵活的能力,使您能够创造任何内容。
- 简单而强大的3D:Godot的3D节点为您提供了构建、动画和渲染3D世界和角色所需的一切。
- 选择适合工作的语言:使用Godot自己的GDScript、C#、C++或使用GDExtension,使用面向对象的API使您的代码模块化。
- 在所有平台上发布:在几秒钟内将游戏部署到桌面、移动设备和Web上。Godot甚至通过第三方支持主机游戏机。
- 专注于2D引擎:使用Godot专用的2D渲染引擎和真实的2D像素坐标和2D节点,制作清晰、高性能的2D游戏。
- 开源真正开放的开发:任何为Godot做出贡献的人都能平等地受益于其他人的贡献。
如果觉得虚幻引擎太过笨重的话,这个引擎看起来还挺不错的,个人感觉画面风格和游戏成品好于gamemaker或者RPGMaker。
关于4步文档模型的问题
什么是4步文档模型(four document model)?
- 教程:描述了如何尽快开始并运行。
- 操作说明:描述了如何完成具体任务。
- 解释:教授您已经深入了解的主题。
- 参考:描述了事物的确切含义和功能。

这有点像在学校里教授的三段式文章:
- 一个起始段落用于介绍背景和主要论点,
- 三个正文段落分别独立支持该论点,
- 一个结论段落用于总结论据和主要论点。
而就像学生学习了三段式文章后的问题一样,4步模型会让文档编写者陷入一个“我只能用这个模型写文档”的想法。
实际上,这个模型至少有两个问题:
不够通用
在4步文档模型的官网上,给了三个典型例子用于说明其模型:
- the Divio Developer Handbook
- Django’s documentation
- django CMS’s documentation
Divio和Django CMS是工具。工具和库与框架和语言不同。工具具有简单的概念模型。只需要知道它们的功能和如何使用它们。4步文档模型最适合反映工具的文档需求。
而Django是框架,框架比工具更高级,它们主要关注的仍然是“什么和如何”,但它们也有许多相互关联的概念需要理解。虽然它在表面上仍遵循4步文档模型,但“解释”部分的长度是教程和操作说明部分长度的三倍。同时,“解释”部分也在教授用户,这本不应该发生。
而如果将4步文档模型应用于编程语言,情况会更加糟糕。看一下Python文档,教程部分需要同时解释和引用,而参考资料既包含解释又包含操作说明。语言概念图太过密集,无法进行分离。
简而言之,4步文档模型并非普适。它是为了记录工具而设计的,无法完全满足框架和编程语言的需求。
不够全面
如果所有有用的文档形式都可以归为这四种类型,那么4步文档模型将是全面的。但由于与4步文档模型不普适的原因相同,这并不成立:它只涵盖了工具所需的文档形式。
如果你要记录一个像编程语言这样复杂的主题,至少还有两种(至少两种)其他类型的文档是你需要的:
- 概念概述
- 代码片段和示例
raylib:一个简单易用的库,让您享受视频游戏编程的乐趣。
raylib受到Borland BGI图形库和XNA框架的启发,特别适用于原型设计、工具开发、图形应用、嵌入式系统和教育领域。
主要feature:
- 无外部依赖,所有必需的库都捆绑在raylib中
- 支持多个平台:Windows、Linux、MacOS、RPI、Android、HTML5…
- 使用普通C代码(C99)编写,使用PascalCase/camelCase表示法
- 通过OpenGL进行硬件加速(支持OpenGL 1.1、2.1、3.3、4.3或ES 2.0)
- 独特的OpenGL抽象层(可作为独立模块使用):rlgl
- 支持多种字体格式(TTF、图像字体、AngelCode字体)
- 支持多种纹理格式,包括压缩格式(DXT、ETC、ASTC)
- 完全支持3D,包括3D形状、模型、广告牌、高度图等等
- 灵活的材质系统,支持经典贴图和PBR贴图
- 支持动画的3D模型(骨骼动画)(IQM)
- 支持着色器,包括模型和后处理着色器。
- 强大的数学模块,用于向量、矩阵和四元数操作:raymath
- 加载和播放音频,支持流媒体(WAV、OGG、MP3、FLAC、XM、MOD)
- 支持配置的VR立体渲染,包括可配置的HMD设备参数
- 庞大的示例集合,包含120多个代码示例
- 对60多种编程语言进行绑定
- 免费且开源
raylib的设计是通过示例作为主要参考来学习。没有标准的API文档,但有一个速查表,其中包含库中所有可用函数的简短描述,输入参数和结果值的名称应该足够直观,以便理解每个函数的工作原理。